作业3:物理信息神经网络求解泊松方程 - 参考题解
作者: 夏省玘
代码与报告: assignment3_report.zip
问题描述
本作业要求使用物理信息神经网络(PINN)求解如下三维空间中的泊松方程:
其中
求解该问题需要以下步骤:
- 搭建一个神经网络模型,模型输入一个三维矢量表示场点
,输出一个标量表示该点电势 。 - 构造一个合适的损失函数,反映一个模型对物理规律的偏差。这里由两条物理规律,分别是泊松方程和边界条件,我们需要在损失函数中同时反映两条规律。
- 生成训练集和测试集。
- 训练神经网络模型,保存训练曲线和模型参数。
- 可视化模型,也就是可视化求解得到的势能函数。我们不需要额外测试测试边界条件和PDE残差,因为它已经记录在了训练曲线中。
然而,仅靠这些步骤不足以获得一个问题的较优解,因为存在以下问题:
- 所用神经网络结构是否合理,能够产生足够复杂的行为拟合所求势函数,而且能够收敛?
- 损失函数如何平衡两条物理规律的权重?
- 如何取训练集和测试集的大小和采样,才能够让模型表现足够良好?
- 边界条件和PDE残差不是衡量势函数是否准确的金标准,与理论解的平方误差才是。因此,只有实现了理论解,才能回答上面三个问题。
为此,我们还需要测试如下超参数:
- 全连接网络的层数
和每层的神经元个数 ; - 训练集每一轮在体内和边界的采样数量
; - 损失函数中两条物理规律的权重比
; - 估算理论解时所用的网格密度与截断项数。
特别注意:物理信息神经网络不允许使用理论解直接参与网络损失的计算。理论解唯一的用处在于验证超参数取值是否合理,从而我们可以使用同样的超参数求解不存在理论解的其它物理问题。
模型设计
本项目所用的神经网络为全连接层神经网络,使用tanh作为激活函数。
每一层隐藏层的宽度相等,均为
FC(3,W) --> Tanh() --> FC(W,W) --> Tanh() --> ... --> FC(W,1)
|<--------共H层隐藏层------->|见pinn_class.py中的PINN类。
损失函数设计
损失函数如下定义:
其中
每epoch,从
需要指出:在我们的代码中,每轮训练评估损失时都会重新采样所有数据点,以增强模型的泛化能力。同时,由于每轮训练都使用与之前不同的数据,因此不需要专门的测试集。
见pinn_class.py中的Loss类。该类同时用于生成训练集。
训练函数
训练流程如下:
- 初始化Loss类(损失函数和训练集)、默认参数的Adam优化器、tensorboard训练曲线记录器、进度条。开始每一步训练。
optimizer.zero_grad():优化器梯度归零;loss_func():生成PDE采样数据点和边界数据点,正向传播,得到势函数值,然后评估PDE损失与边界损失;- 记录当前的PDE损失和边界损失;
loss = loss_pde + beta * loss_bc:合成总损失;- 如果当前的总损失历史最小,那么保存模型;
loss.backward():反向传播总损失,获得每个模型参数的梯度信息;optimizer.step():使用Adam优化器优化模型参数;- 更新进度条;
- 进入下一步训练,直至训练结束。
- 保存最终模型。
见pinn_class.py中的train()函数。
可视化方案
对于训练过程中的PDE损失和边界损失,我们直接使用tensorboard作为现成的可视化方案。运行tensorboard --logdir ./results/log/,将6006端口SSH转发到本地端口,然后使用浏览器访问对应的本地端口,即可看到损失曲线。
合适参数大小模型的训练曲线: 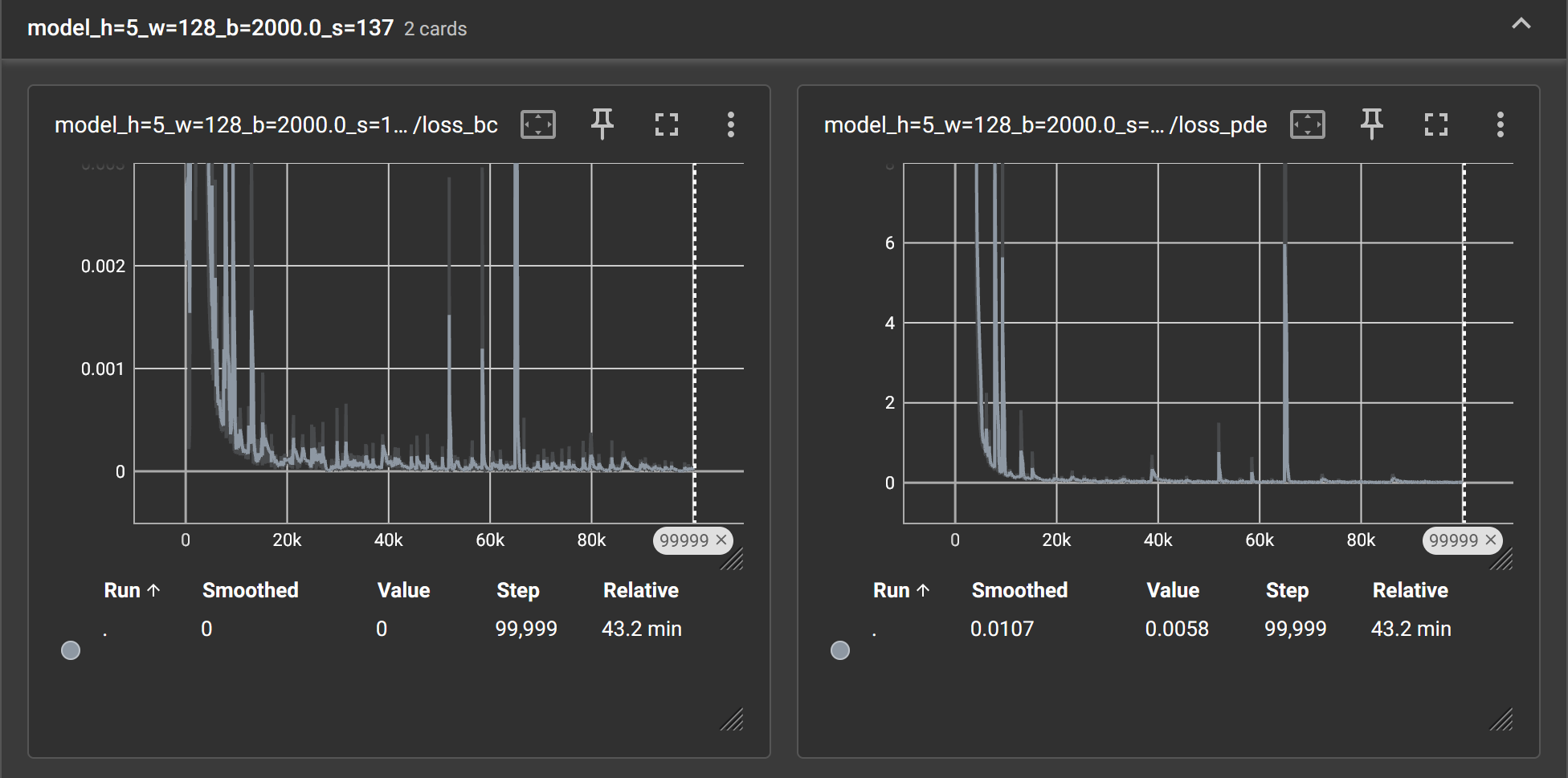
模型过小时,会发生欠拟合: 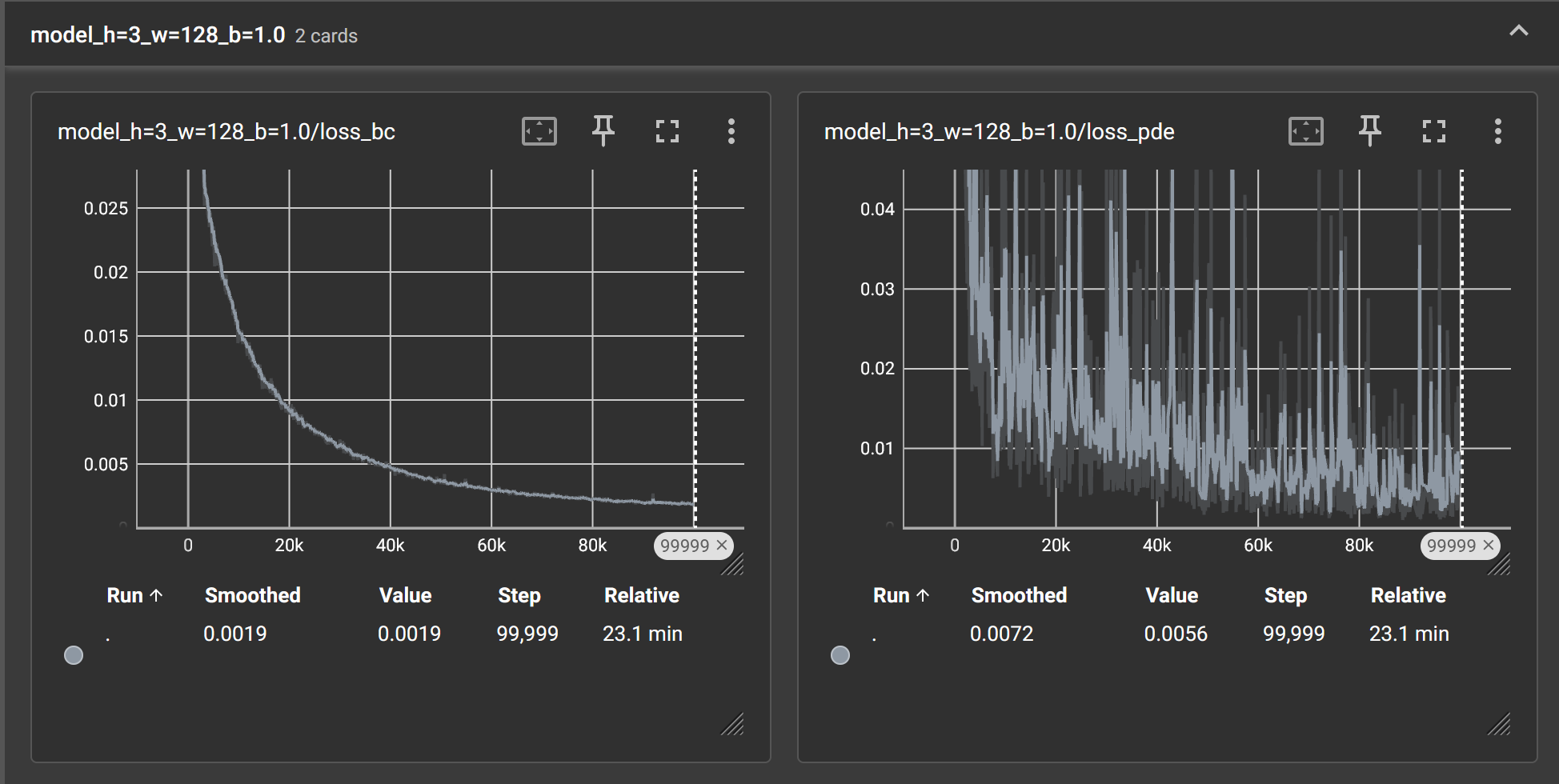
模型过大时,训练将不收敛: 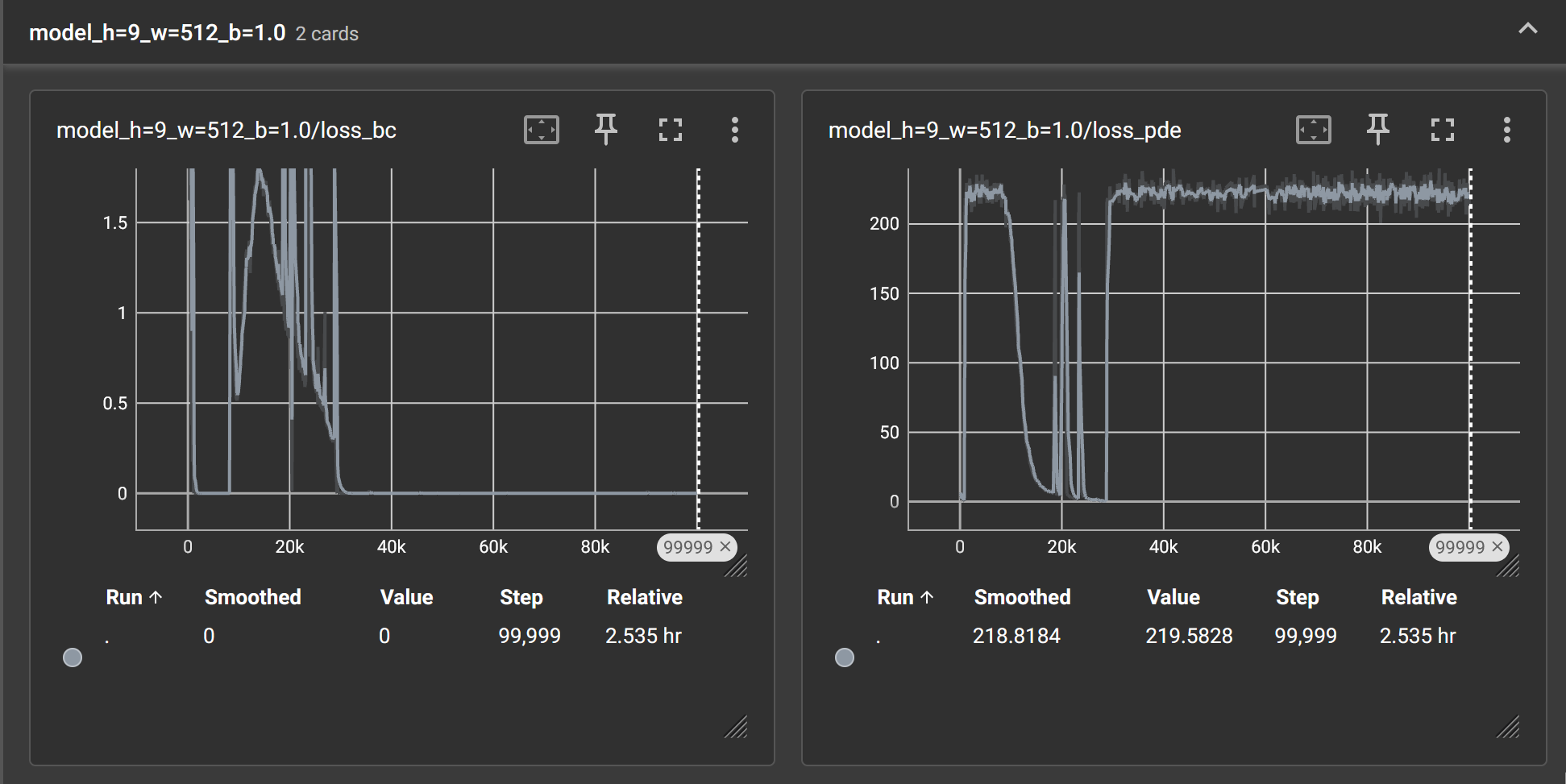
对于模型势函数的可视化,我们取“平行于xOz平面、y=-0.5,0.2,0.8”的截面,和“平行于xOy平面、z=-0.5,0.2,0.8”的截面,在二维平面上绘制函数在所选截面上的值,用颜色表示高度,用白色曲线标出等高线。
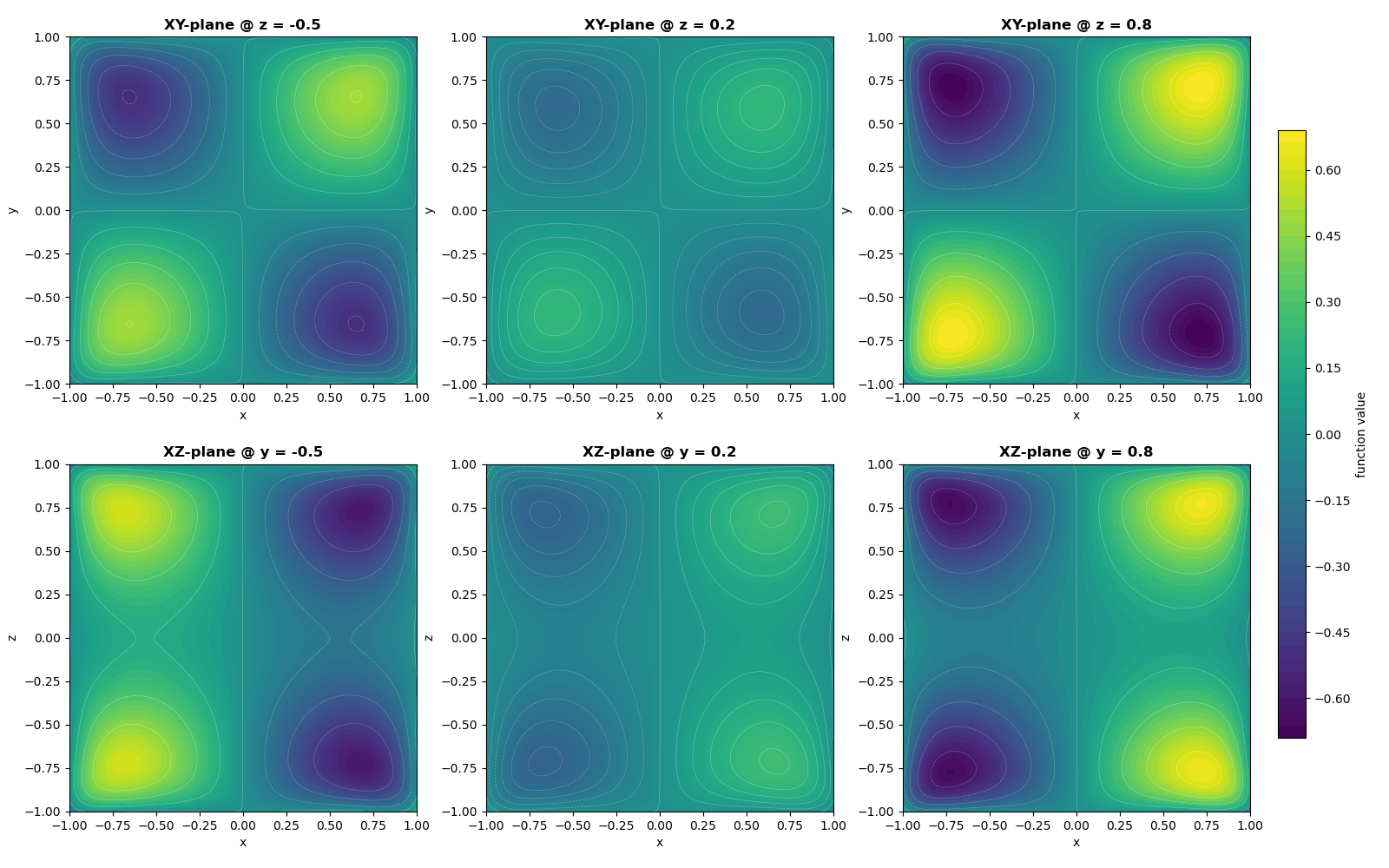
绘制该截面图的代码见plot_evaluation.py文件的plot_ternary_function_advanced()函数。
金标准的构建
当改变
考虑定解问题
通过分离变量法,可以求得级数形式的严格解:
我们在strict_solution_data.npz,包含了所有1,000,000个格点的坐标和这些位置的级数求和。
上述严格解计算代码,见strict_solution.py。
有了这些格点上函数的取值之后,我们就可以估计每一个模型与严格解之间的平方误差。
需要注意:1.该误差与评分标准中的误差表达式有细微的差别;2.由于使用了截断的无穷级数估计
调用Loss类评估已训练模型的PDE误差、边界误差,并计算上述平方误差的代码,见loss_evaluation.py。
搜索模型的最佳超参数
为了找到模型最佳的超参数,我首先实现了批量并行训练模型的代码。在batch_train.py中,我使用了torch.multiprocessing.spawn函数,向服务器的10块显卡分配训练任务,每个训练任务都指定了不同的
然而,由于我没有使用多元函数优化算法进行系统性的优化,而是凭感觉在人工最优参数的可能取值的邻域内撒点,因此实际上找到的参数大概率不是严格最优的,只是一个较优的取值。
第一次搜索
为了大致寻找最优参数可能的范围,我以batch_train.py中main_1()函数。
当模型每层神经元个数
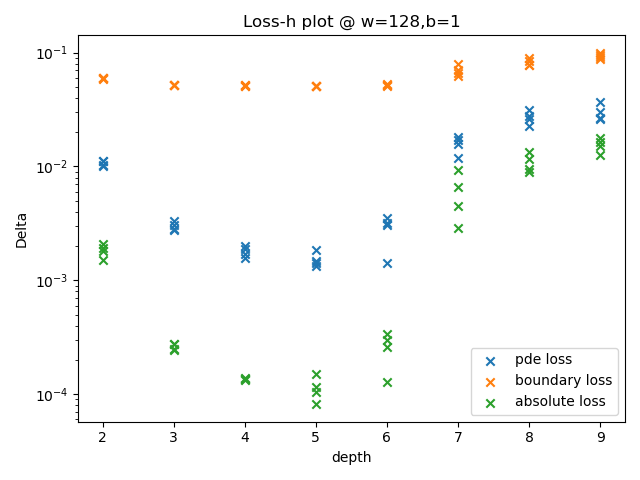
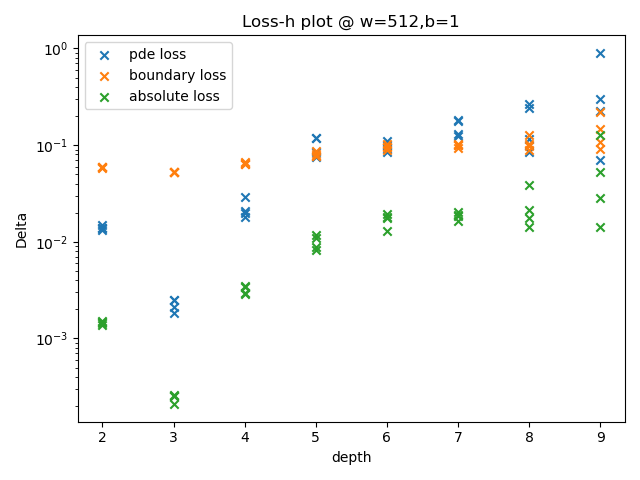
图中,绿色散点为平方误差。由该数据的变化趋势可以得出结论:
当每层神经元个数为128时,隐藏层数为5的模型表现最好,隐藏层数为4与6的模型次之,隐藏层数过深和过浅都会导致模型表现下降;
当每层神经元个数为512时,深度为3的模型表现最好,且远好于其它深度的模型。但此时模型的表现略逊于隐藏层数为5、神经元个数为128的模型。
当模型隐藏层数为5、
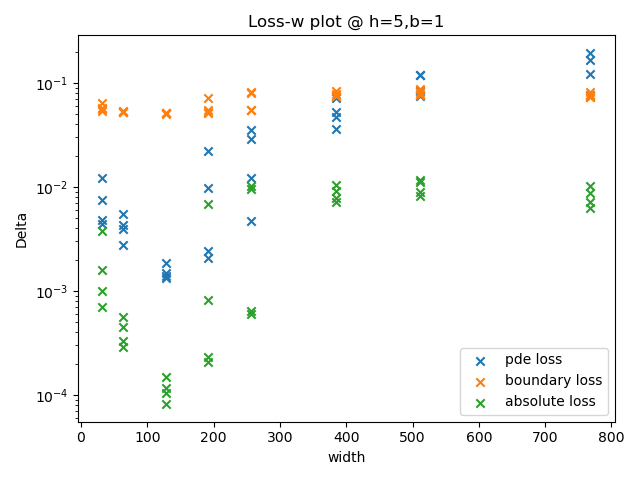
由此得出结论:当模型隐藏层数为5时,每层神经元个数为128的模型表现最好。
结合前一部分,我的第一次尝试就恰好击中了
当模型隐藏层数为5、每层神经元个数为128时,在
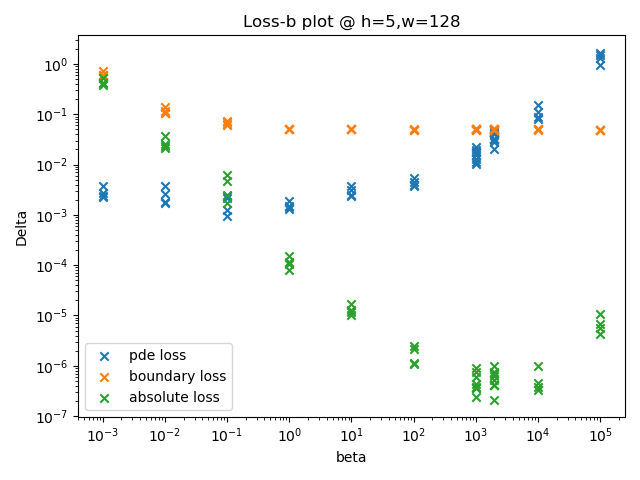
(图中
随着边界损失和PDE损失在总损失中的占比上升,首先边界损失剧烈下降后趋于平缓,然后PDE损失不再平缓并开始剧烈上升。
非常值得关注的一点是,平方损失最小的点并不在边界损失和PDE损失都趋于平缓的临界点
这意味着边界损失相较于PDE损失更加“重要”。这也意味着单靠PDE损失和边界损失,尽管可能可以优化出足够接近最优解的模型参数取值,也不足以让我们找到最优的超参数取值。
第二次搜索
在发现batch_train.py中main_2()函数。
结果如下:
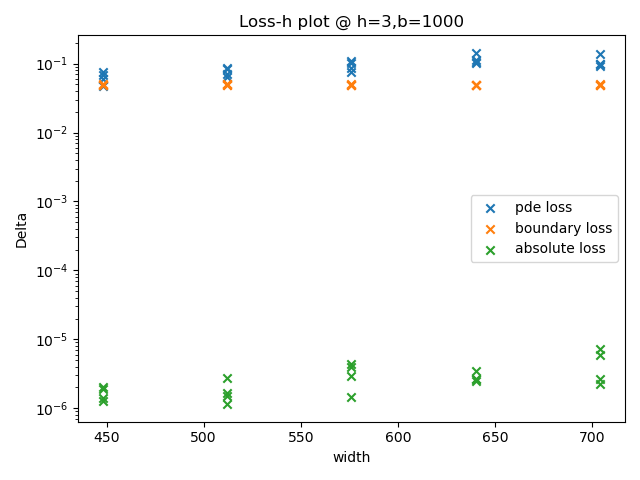
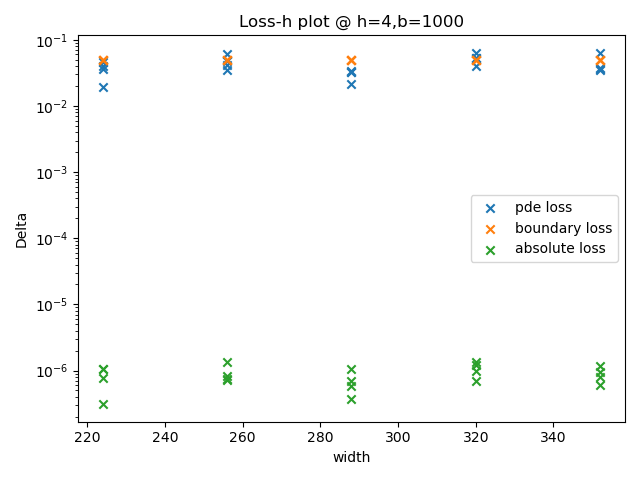
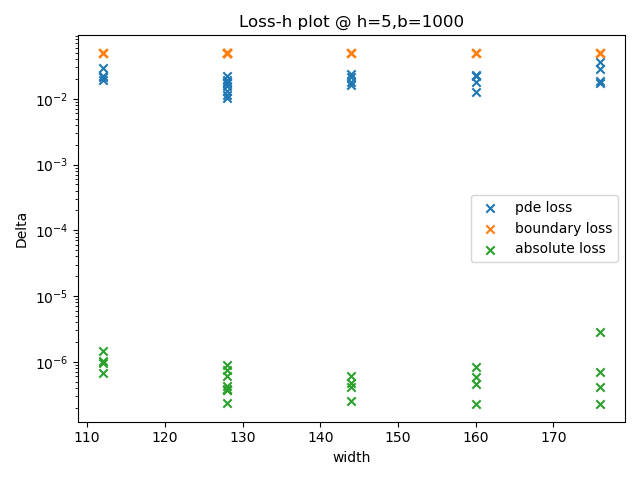
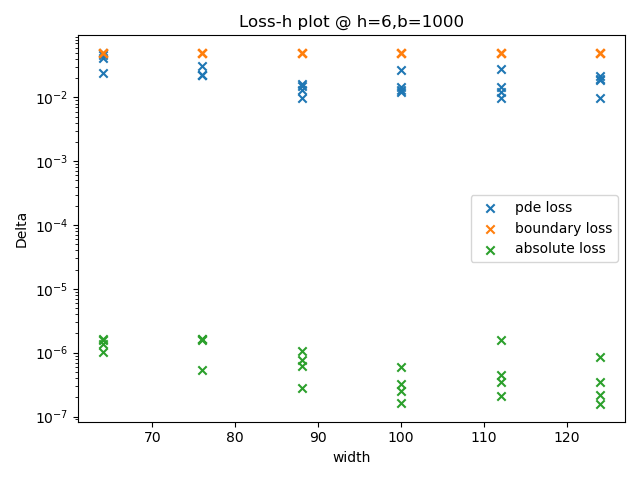
结果显示:当每层神经元个数在最优值附近时,该超参数对模型的表现没有显著影响。纵向比较上述四张图,当隐藏层层数
此外,第二次搜索中,我还在(h=3,w=448)和(h=5,w=128)两个点附近搜索了
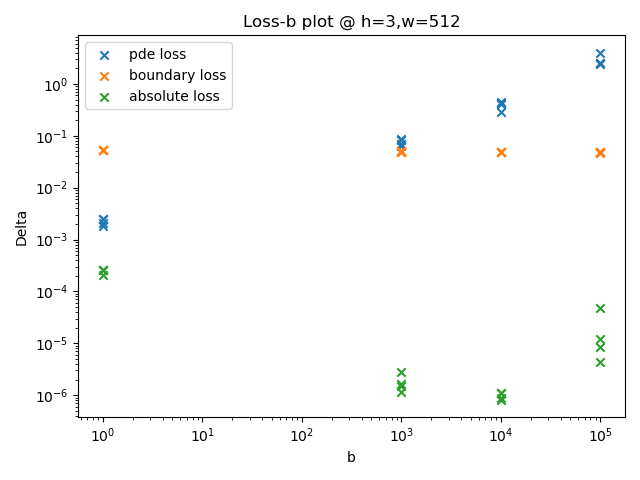
结果给出了两组较优参数组合:batch_train.py中main_3()函数。
绘制本部分散点图的代码见analysis_evaluation.py。
总结
完成作业
- 模型设计:全连接层神经网络,使用tanh作为激活函数,隐藏层的宽度均为
;隐藏层层数为 。 - 损失函数:边界损失与PDE损失的线性组合,二者权重比为
。 - 训练集:域内采样点
、边界采样点 ,每轮重新采样。 - 测试集:不需要测试集。
- 优化器:默认参数的Adam优化器。
- 可视化方案:tensorboard网页截图、绘制多个截面内函数取值
追求更优
- 严格解估算:分离变量法得到无穷级数,将级数截断到100阶,计算在均匀立方格点上样本点的级数值。
- 搜索最佳参数:并行批量训练,手动选取训练参数,以与严格解的平方误差作为判断标准;(h=5,w=128,β=2000)(h=3,w=448,β=10,000)和(h=6,w=100,β=1000)都是比较好的超参数值。(题目中的β定义要取倒数)